

If you do not know what an ADT is, read the previous post - https://blog.hyper.io/understanding-adts/
In a previous post, we talked about ADTs or Algebraic Data Types, these types enable you to create a data flow pipeline process in a safe container-like environment.
TL;DR; Async ADTs wrap functions so you can separate side effects from business logic or actions from calculations, resulting in highly maintainable and testable code.
Who is this post for?
- Developers who are interested in learning functional programming but may be struggling to see why to use another async tool.
- Have created maintenance nightmares and is interested in finding a better way to build software.
- Tired of the needle in the haystack syndrome for every user reported bug, it should not be hard to locate problems with good design.
What will I learn?
- You will learn how to separate side effects (actions) from business logic (calculations) in a sane and manageable way.
- You will learn that wrapping async functions and applying functions to their future values is not hard and has a lot of value in your day-to-day development.
Rather watch than read, checkout this video:
Why Async ADTs? Clean Architecture
Before we dive into the Async ADT, let's talk about clean code and clean architecture. To create highly maintainable, extendable, and reliable software we need to separate our business logic from our implementation details and our actions from our calculations.
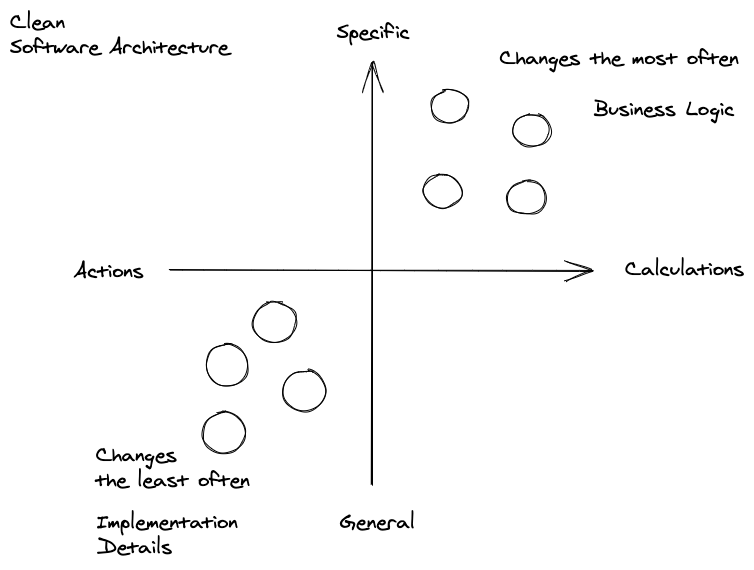
Clean Architecture is hard!
Using interfaces and inversion of control, or dependency injection can help separate our business logic from our implementation details, but we still have the challenge of actions or side effect functionality.
How do we isolate our business logic into pure functions and separate them from side effect functions?
The Flux architecture is one pattern that helps with this, but it does require some boilerplate and is not a great fit because flux tends to start to spread logic around in separate functions to complete one flow. Reducers, ActionCreators, and Selectors for example.
Another is ADT's. ADTs are all about managing values inside containers, what if that value was a function.
Introducing the Async ADT
The Async ADT separates your side effect functions from your pure functions by wrapping the side effect function in a function and treating it like a value in a container. ADTs are container objects, that allows us to manage values so that no nulls or mutations can occur without the explicit methods being invoked to the ADT.
ADTs are made up of map and chain functions
The map method enables the developer to apply a function that receives the current value inside the container as an input argument and then replaces the value inside the container with the returned output from the function.
[1].map(v => 2) // -> [2]An ADT contains a value of 1 and the map function is called that returns a value of 2, the ADT now contains the value of 2.
The chain method allows the developer to apply a function that receives the current value in the container as input and then replaces the whole container with the returned output from the function which must be of the same ADT Type. (in the example flatMap is chain)
[2].flatMap(v => [4]) // -> [4]ADTs contains values for pipeline like flow for logic processing, functions are values, so we can take advantage of the ADT pattern to pass functions around.
Functions are values
In the past, if you have learned about Javascript, you should know that functions are values, they can be passed to other functions as arguments and can be returned from functions as output.
Instead of using a number or string as a value, let's use a function as a value?
The ADT pipeline can operate on that function using map and chain, but never actually execute the function, until a function is called to trigger the execution of the function, the fork method calls the function.
const fn = (rejected, resolved) => resolved('Hello')
const fork = [fn].map(fn => (rejected, resolved) =>
resolved(fn(e => e, r => r + ' World' ))
)
.pop()
fork(e => e, r => console.log(r))
In this example, we create a function that takes two arguments, the first argument is called rejected and is a unary function and the second argument is called resolved and is a unary function.
/**
* @param {function} rejected - unary function for rejected Asyncs
* @param {function} resolved - unary function for resolved Asyncs
*/
function (rejected, resolved) {
return value
}The Async function can return any value when called, in the example, the return value is the string Hello.
Now place this function as a value in the container. Just like any value in the container, we can run map or chain on the container.
When map runs, the value that is provided as the argument is the async function, and returns another function that is the same signature of the async function that becomes the replaced value of the container.
With this call flow, composing async functions is a result of each one calling the previous one, like composition, when the fork method is invoked it will unwind all of the previously composed functions until a final value is determined and returned either in the first argument as a rejected result or the second argument as a resolved result.
This lazy call flow is super confusing and would be a chore to write by hand.
When returning functions as values you start to create a pipeline, where one function calls another function, then the result of that function is called with another function, down the line, but the functions are not called until the fork method is run, this creates a lazy execution environment, or zero side effect environment because no side effects are actually executed until fork is called.
Because we are passing pure functions which never execute side effects until the fork function is called, creating business logic without side effects (pure functions). The embedded side effect functions execute on the edge of the application in a single fork call.
Using the array starts to show how this working, but we can do better, we can create an ADT called a Async.
Async is an ADT designed to wrap async functions in a container for pure function processing
Async will handle the boilerplate function wrapping, and enable the developer to write an ADT as if the values are actually returned and can be modified using map and chain methods.
const Async = fork =>
({
fork,
map: fn => Async((rejected, resolved) =>
fork(rejected, v => resolved(fn(v)))
)
})
Async.of = v => Async((rejected, resolved) => resolved(v))Let's just create an ADT with a function for starters to keep things simple.
Remember, the Async method takes a function with the signature of (rejected, resolved )=> any.
This ADT will allow us to work with Async function values as if the value is provided in the map and returns a new value in the map. The ADT will manage the wrapping of functions for us. (Yay!)
Async.of(1)
.map(v => v + 1)
.fork(e => console.log('rej: ', e), r => console.log(r))
// -> 2Neat!
The super cool result of the Async ADT is the actual execution does not occur until the fork function is called. (Yay! no side effects in my business logic!) The wrapping of values into the async function occurs in the ADT so the authoring developer can create pipelines as if they are managing the actual values instead of the async functions. (No Side Effects)
What about side effects?
A promise is a common pattern for creating functions that contain side effects.
const sideEffect = () => Promise.resolve(1)
Async.fromPromise = fn => Async((rejected, resolved) => fn().then(resolved).catch(rejected))
Async.fromPromise(sideEffect)
.map(v => v + 1)
.fork(e => console.log('rej: ', e), r => console.log('res: ' + r))
In this example, we create an Async ADT from a promise, then we call map and actually work on the value that will be resolved from that promise. The returning value gets wrapped into an Async function.
The Async ADT has two potential outcomes for a pipeline, rejected and resolved. Once a rejected function is called in the pipeline all other chained methods are bypassed and when the fork method is invoked the first function in the argument list is invoked. As long as resolved methods are invoked the chain will continue to be followed all the way down to the second function in the fork argument list is invoked.
Let's add a chain function to our Async ADT. A chain method takes a function that provides the value as the argument of the function and returns a new Async to replace the current Async.
The developer does not have to worry about the resolved or rejected function signature, the ADT extracts the value and then replaces the current Async with the newly returned Async.
const Async = fork =>
({
fork,
map: fn => Async((rejected, resolved) =>
fork(rejected, v => resolved(fn(v))
)),
chain: fn => Async((rejected, resolved) =>
fork(rejected, x => fn(x).fork(rejected, resolved))
)
})We can demonstrate the functionality.
Async.of(4)
.chain(v => Async.of(v + 1))
.fork(
e => console.log(`rej: ${e}`),
r => console.log(`res: ${r}`)
)
Pretty cool, working with Async ADTs is just like working with Id ADTs. No need to worrying about the side effect functions, those side effects don't execute during our business logic, only when fork is called, which would be called in your interface layer, not in your business logic core.
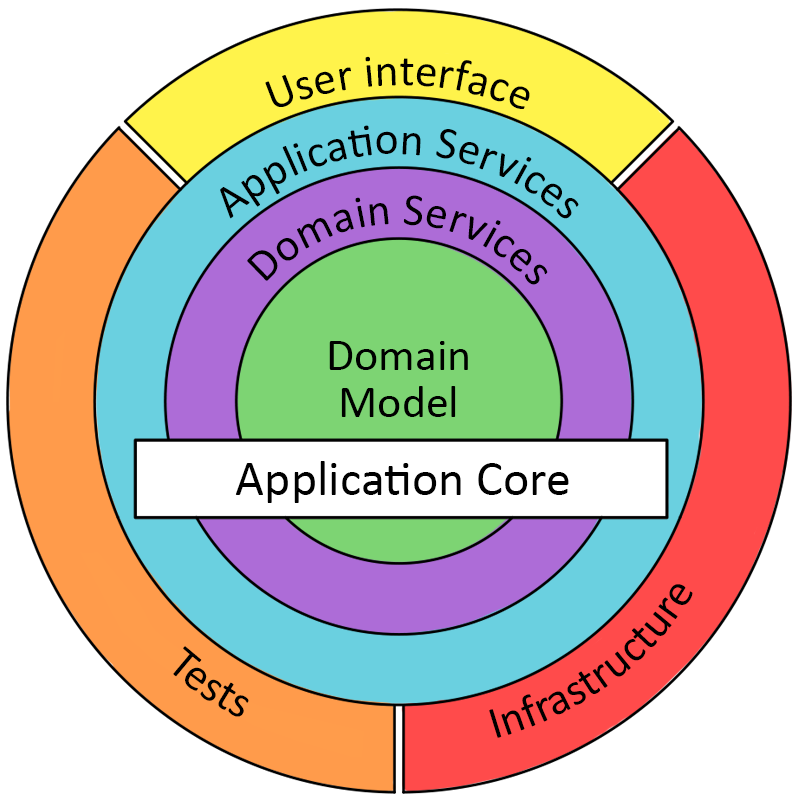
By leveraging Async ADTs you can return service layer calls to your core and allow the interface to invoke your core logic functions and receive Async ADTs. And when the interface is ready, it can invoke the ADT with the fork function, this flow keeps your application core pure and keeps the side effects running at the edges of your application, not within the core business logic.
Summary
How can we separate side effect (actions) functions from pure business logic (calculations) functions without having to add a lot of boilerplate management?
The answer is Async ADTs
Async ADTs are the building blocks for clean architecture. For an example of using Async ADTs checkout: https://github.com/hyper63/workshop-api